Connect to SQL database Data Assets
Use the information provided here to connect to Data Assets stored in SQL databases. Great Expectations (GX) uses SQLAlchemy to connect to SQL Data Assets, and most of the SQL dialects supported by SQLAlchemy are also supported by GX. For more information about the SQL dialects supported by SQLAlchemy, see Dialects.
- Snowflake
- PostgreSQL
- SQLite
- Databricks SQL
- BigQuery SQL
- Generic SQL
Snowflake
Connect GX to a Snowflake database to access Data Assets.
Prerequisites
- An installation of GX set up to work with SQL
- Source data stored in a Snowflake database
Import GX and instantiate a Data Context
Run the following Python code to import GX and instantiate a Data Context:
import great_expectations as gx
context = gx.get_context()
Determine your connection string
The following code examples use a Snowflake connection string. A Snowflake connection string connects GX to the Snowflake database.
The following code is an example of a Snowflake connection string format:
my_connection_string = "snowflake://<USER_NAME>:<PASSWORD>@<ACCOUNT_NAME_OR_LOCATOR>/<DATABASE_NAME>/<SCHEMA_NAME>?warehouse=<WAREHOUSE_NAME>&role=<ROLE_NAME>"
Snowflake accepts both account names and account locators as valid account identifiers when constructing a connection string.
Account names uniquely identify an account within your organization and are the preferred method of account identification.
Account locators act in the same manner but are auto-generated by Snowflake based on the cloud platform and region used.
For more information on both methods, see Account Identifiers
Create a Snowflake Data Source
-
Run the following Python code to set the
nameandconnection_stringvariables:datasource_name = "my_snowflake_datasource" -
Run the following Python code to create a Snowflake Data Source:
datasource = context.sources.add_snowflake(
name=datasource_name,
connection_string=my_connection_string, # Or alternatively, individual connection args
)
connection_stringAlthough a connection string is the standard way to yield a connection to a database, the Snowflake datasource supports individual connection arguments to be passed in as an alternative.
The following arguments are supported:
accountuserpassworddatabaseschemawarehouserolenumpy
Passing these values as keyword args to add_snowflake is functionally equivalent to passing in a connection_string.
For more information, check out Snowflake's official documentation on the Snowflake SQLAlchemy toolkit.
Connect to the data in a table (Optional)
-
Run the following Python code to set the
asset_nameandasset_table_namevariables:asset_name = "my_asset"
asset_table_name = "my_table_name" -
Run the following Python code to create the Data Asset:
table_asset = datasource.add_table_asset(name=asset_name, table_name=asset_table_name)
Connect to the data in a query (Optional)
-
Run the following Python code to define a Query Data Asset:
asset_name = "my_query_asset"
query = "SELECT * from yellow_tripdata_sample_2019_01" -
Run the following Python code to create the Data Asset:
query_asset = datasource.add_query_asset(name=asset_name, query=query)
Add additional tables or queries (Optional)
Repeat the previous steps to add additional Data Assets.
PostgreSQL
Connect GX to a PostgreSQL database to access Data Assets.
Prerequisites
- An installation of GX set up to work with PostgreSQL
- Source data stored in a PostgreSQL database
Import GX and instantiate a Data Context
Run the following Python code to import GX and instantiate a Data Context:
import great_expectations as gx
context = gx.get_context()
Determine your connection string
The following code examples use a PostgreSQL connection string. A PostgreSQL connection string connects GX to the PostgreSQL database.
The following code is an example of a PostgreSQL connection string format:
my_connection_string = (
"postgresql+psycopg2://<username>:<password>@<host>:<port>/<database>"
)
We recommend that database credentials be stored in the config_variables.yml file, which is located in the uncommitted/ folder by default, and is not part of source control. The following lines add database credentials under the key db_creds.
db_creds:
drivername: postgres
host: '<your_host_name>'
port: '<your_port>'
username: '<your_username>'
password: '<your_password>'
database: '<your_database_name>'
For additional options on configuring the config_variables.yml file or additional environment variables, please see our guide on how to configure credentials.
Create a PostgreSQL Data Source
-
Run the following Python code to set the
nameandconnection_stringvariables:Pythondatasource_name = "my_datasource"
my_connection_string = (
"postgresql+psycopg2://<username>:<password>@<host>:<port>/<database>"
) -
Run the following Python code to create a PostgreSQL Data Source:
Pythondatasource = context.sources.add_postgres(
name=datasource_name, connection_string=my_connection_string
)
Connect to a specific set of data with a Data Asset
To connect the Data Source to a specific set of data in the database, you define a Data Asset in the Data Source. A Data Source can contain multiple Data Assets. Each Data Asset acts as the interface between GX and the specific set of data it is configured for.
With SQL databases, you can use Table or Query Data Assets. The Table Data Asset connects GX to the data contained in a single table in the source database. The Query Data Asset connects GX to the data returned by a SQL query.
Although there isn't a maximum number of Data Assets you can define for a Data Source, you must create a single Data Asset to allow GX to retrieve data from your Data Source.
Connect a Data Asset to the data in a table (Optional)
-
Run the following Python code to identify the table to connect to with a Table Data Asset:
Pythonasset_name = "my_table_asset"
asset_table_name = "postgres_taxi_data" -
Run the following Python code to create the Data Asset:
Pythontable_asset = datasource.add_table_asset(name=asset_name, table_name=asset_table_name)
Connect a Data Asset to the data returned by a query (Optional)
-
Run the following Python code to define a Query Data Asset:
Pythonasset_name = "my_query_asset"
asset_query = "SELECT * from postgres_taxi_data" -
Run the following Python code to create the Data Asset:
Pythonquery_asset = datasource.add_query_asset(name=asset_name, query=asset_query)
Connect to additional tables or queries (Optional)
Repeat the previous steps to add additional Data Assets.
SQLite
Connect GX to a SQLite database to access Data Assets.
Prerequisites
- An installation of GX set up to work with SQLite
- Source data stored in a SQLite database
Import GX and instantiate a Data Context
Run the following Python code to import GX and instantiate a Data Context:
import great_expectations as gx
context = gx.get_context()
Determine your connection string
The following code examples use a SQLite connection string. A SQLite connection string connects GX to the SQLite database.
The following code is an example of a SQLite connection string format:
my_connection_string = "sqlite:///<path_to_db_file>"
Create a SQLite Data Source
-
Run the following Python code to set the
nameandconnection_stringvariables:Pythondatasource_name = "my_datasource" -
Run the following Python code to create a SQLite Data Source:
Pythondatasource = context.sources.add_sqlite(
name=datasource_name, connection_string=my_connection_string
)Usingadd_sql(...)instead ofadd_sqlite(...)The SQL Data Source created with
add_sqlcan connect to data in a SQLite database. However,add_sqlite(...)is the preferred method.SQLite stores datetime values as strings. Because of this, a general SQL Data Source sees datetime columns as string columns. A SQLite Data Source has additional handling in place for these fields, and also has additional error reporting for SQLite specific issues.
If you are working with SQLite Data Source, use
add_sqlite(...)to create your Data Source.
Connect to the data in a table (Optional)
-
Run the following Python code to set the
asset_nameandasset_table_namevariables:Pythonasset_name = "my_asset"
asset_table_name = my_table_name -
Run the following Python code to create the Data Asset:
Pythontable_asset = datasource.add_table_asset(name=asset_name, table_name=asset_table_name)
Connect to the data in a query (Optional)
-
Run the following Python code to define a Query Data Asset:
Pythonasset_name = "my_query_asset"
query = "SELECT * from yellow_tripdata_sample_2019_01" -
Run the following Python code to create the Data Asset:
Pythonquery_asset = datasource.add_query_asset(name=asset_name, query=query)
Add additional tables or queries (Optional)
Repeat the previous steps to add additional Data Assets.
Databricks SQL
Connect GX to Databricks to access Data Assets.
Prerequisites
- An installation of GX set up to work with SQL
- Source data stored in a Databricks cluster
Import GX and instantiate a Data Context
Run the following Python code to import GX and instantiate a Data Context:
import great_expectations as gx
context = gx.get_context()
Determine your connection string
The following code examples use a Databricks SQL connection string. A connection string connects GX to Databricks.
The following code is an example of a Databricks SQL connection string format:
my_connection_string = f"databricks://token:{token}@{host}:{port}/{database}?http_path={http_path}&catalog={catalog}&schema={schema}"
Create a Databricks SQL Data Source
-
Run the following Python code to set the
nameandconnection_stringvariables:datasource_name = "my_databricks_sql_datasource" -
Run the following Python code to create a Snowflake Data Source:
datasource = context.sources.add_databricks_sql(
name=datasource_name,
connection_string=my_connection_string,
)
Connect to the data in a table (Optional)
-
Run the following Python code to set the
asset_nameandasset_table_namevariables:asset_name = "my_asset"
asset_table_name = my_table_name -
Run the following Python code to create the Data Asset:
table_asset = datasource.add_table_asset(name=asset_name, table_name=asset_table_name)
Connect to the data in a query (Optional)
-
Run the following Python code to define a Query Data Asset:
asset_name = "my_query_asset"
query = "SELECT * from yellow_tripdata_sample_2019_01" -
Run the following Python code to create the Data Asset:
query_asset = datasource.add_query_asset(name=asset_name, query=query)
Add additional tables or queries (Optional)
Repeat the previous steps to add additional Data Assets.
BigQuery SQL
Integrate GX with Google Cloud Platform (GCP).
The following scripts and configuration files are used in the examples:
-
The local GX configuration is located in the
great-expectationsGIT repository. -
The script to test the BigQuery configuration is located in gcp_deployment_patterns_file_bigquery.py.
-
The script to test the GCS configuration is located in gcp_deployment_patterns_file_gcs.py.
Prerequisites
- An installation of GX set up to work with SQL.
- Familiarity with Google Cloud Platform features and functionality.
- A GCP project with a running Google Cloud Storage container that is accessible from your region.
- Read/write access to a BigQuery database.
- Access to a GCP Service Account with permission to access and read objects in Google Cloud Storage.
When installing GX in Composer 1 and Composer 2 environments the following packages must be pinned:
[tornado]==6.2
[nbconvert]==6.4.5
[mistune]==0.8.4
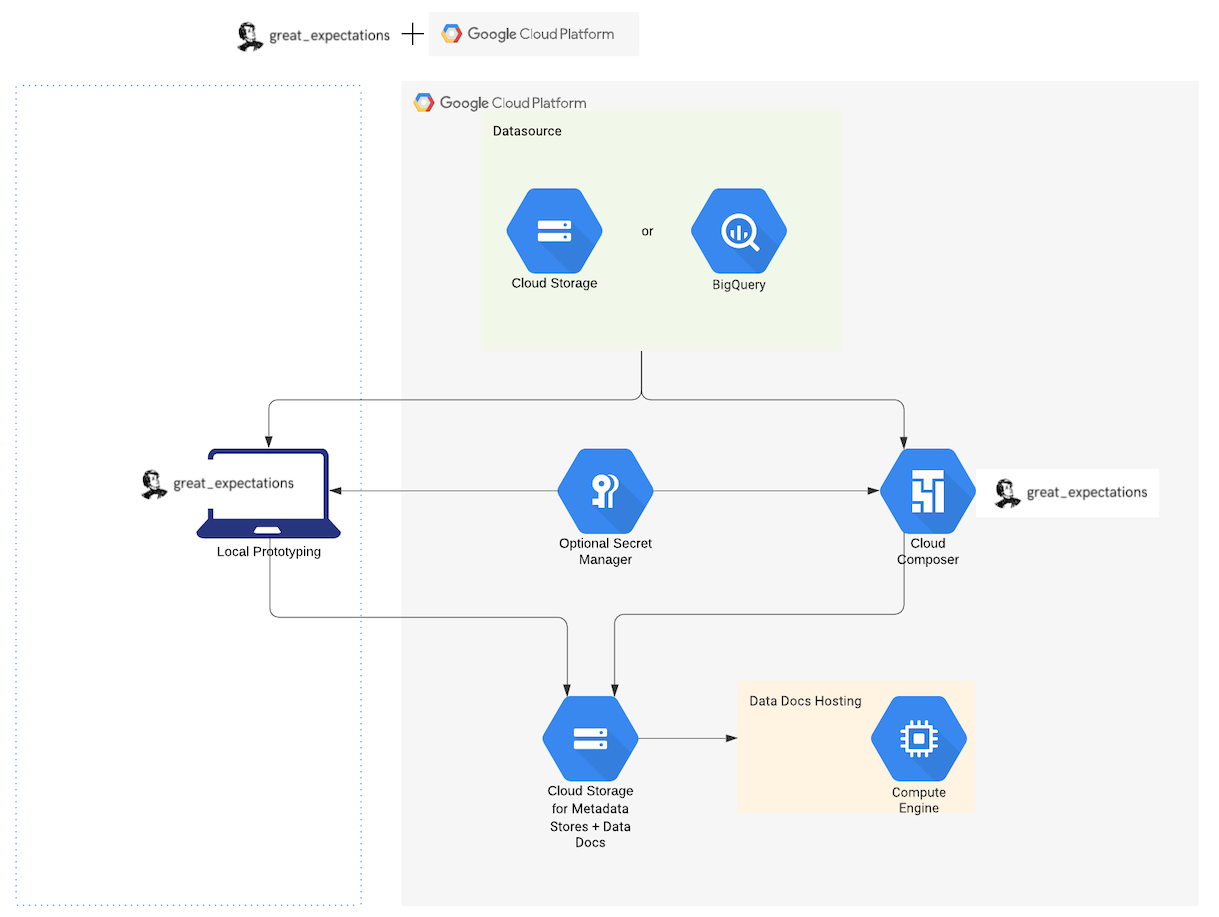
GX recommends that you use the following services to integrate GX with GCP:
-
Google Cloud Composer (GCC) for managing workflow orchestration including validating your data. GCC is built on Apache Airflow.
-
BigQuery or files in Google Cloud Storage (GCS) as your Data SourceProvides a standard API for accessing and interacting with data from a wide variety of source systems..
-
GCS for storing metadata (Expectation SuitesA collection of verifiable assertions about data., Validation ResultsGenerated when data is Validated against an Expectation or Expectation Suite., Data DocsHuman readable documentation generated from Great Expectations metadata detailing Expectations, Validation Results, etc.).
-
Google App Engine (GAE) for hosting and controlling access to Data DocsHuman readable documentation generated from Great Expectations metadata detailing Expectations, Validation Results, etc..
The following diagram shows the recommended components for a GX deployment in GCP:
Upgrade your GX version (Optional)
Run the following code to upgrade your GX version:
pip install great-expectations --upgrade
Get DataContext
Run the following code to create a new Data ContextThe primary entry point for a Great Expectations deployment, with configurations and methods for all supporting components.:
import great_expectations as gx
context = gx.data_context.FileDataContext.create(full_path_to_project_directory)
The full_path_to_project_directory parameter can be an empty directory where you intend to build your GX configuration.
Connect to GCP Metadata Stores
The code examples are located in the great-expectations repository.
When specifying prefix values for Metadata Stores in GCS, don't add a trailing slash /. For example, prefix: my_prefix/. When you add a trailing slash, an additional folder with the name / is created and metadata is stored in the / folder instead of my_prefix.
Add an Expectations Store
By default, newly profiled Expectations are stored in JSON format in the expectations/ subdirectory of your gx/ folder. A new Expectations Store can be configured by adding the following lines to your great_expectations.yml file. Replace the project, bucket and prefix with your values.
stores:
expectations_store:
class_name: ExpectationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: expectations/
expectations_store_name: expectations_store
To configure GX to use this new Expectations Store, expectations_GCS_store, set the expectations_store_name value in the great_expectations.yml file.
stores:
expectations_GCS_store:
class_name: ExpectationsStore
store_backend:
class_name: TupleGCSStoreBackend
project: <your>
bucket: <your>
prefix: <your>
expectations_store_name: expectations_GCS_store
Add a Validations Store
By default, Validations are stored in JSON format in the uncommitted/validations/ subdirectory of your gx/ folder. You can connfigure a new Validations Store by adding the following lines to your great_expectations.yml file. Replace the project, bucket and prefix with your values.
stores:
validations_store:
class_name: ValidationsStore
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: uncommitted/validations/
validations_store_name: validations_store
To configure GX to use the new validations_GCS_store Validations Store, set the validations_store_name value in the great_expectations.yml file.
stores:
validations_GCS_store:
class_name: ValidationsStore
store_backend:
class_name: TupleGCSStoreBackend
project: <your>
bucket: <your>
prefix: <your>
validations_store_name: validations_GCS_store
Add a Data Docs Store
To host and share Data Docs on GCS, see Host and share Data Docs.
After you have hosted and shared Data Docs, your great-expectations.yml contains the following configuration below data_docs_sites:
data_docs_sites:
local_site:
class_name: SiteBuilder
show_how_to_buttons: true
store_backend:
class_name: TupleFilesystemStoreBackend
base_directory: uncommitted/data_docs/local_site/
site_index_builder:
class_name: DefaultSiteIndexBuilder
gs_site: # this is a user-selected name - you may select your own
class_name: SiteBuilder
store_backend:
class_name: TupleGCSStoreBackend
project: <your>
bucket: <your>
site_index_builder:
class_name: DefaultSiteIndexBuilder
Run the following command in the gcloud CLI to view the deployed DataDocs site:
gcloud app browse
The URL to your app appears and opens in a new browser window. You can view the index page of your Data Docs site.
Connect to a Data Source
Connect to a GCS or BigQuery Data Source.
- Data in GCS
- Data in BigQuery
Run the following code to add the name of your GCS bucket to the add_pandas_gcs function:
datasource = context.sources.add_pandas_gcs(
name="gcs_datasource", bucket_or_name="test_docs_data"
)
In the example, you've added a Data Source that connects to data in GCS using a Pandas dataframe. The name of the new datasource is gcs_datasource and it refers to a GCS bucket named test_docs_data.
Tables that are created by BigQuery queries are automatically set to expire after one day.
Run the following code to create a Data Source that connects to data in BigQuery:
datasource = context.sources.add_or_update_sql(
name="my_bigquery_datasource",
connection_string="bigquery://<gcp_project_name>/<bigquery_dataset>",
)
In the example, you created a Data Source named my_bigquery_datasource, using the add_or_update_sql method and passed it in a connection string.
Create Assets
- Data in GCS
- Data in BigQuery
Use the add_csv_asset function to add a CSV Asset to your Data Source.
Configure the prefix and batching_regex. The prefix is the path to the GCS bucket where the files are located. batching_regex is a regular expression that indicates which files should be treated as Batches in the Asset, and how to identify them. For example:
batching_regex = r"yellow_tripdata_sample_(?P<year>\d{4})-(?P<month>\d{2})\.csv"
prefix = "data/taxi_yellow_tripdata_samples/"
In the example, the pattern r"data/taxi_yellow_tripdata_samples/yellow_tripdata_sample_(?P<year>\d{4})-(?P<month>\d{2})\.csv" builds a Batch for the following files in the GCS bucket:
test_docs_data/data/taxi_yellow_tripdata_samples/yellow_tripdata_sample_2019-01.csv
test_docs_data/data/taxi_yellow_tripdata_samples/yellow_tripdata_sample_2019-02.csv
test_docs_data/data/taxi_yellow_tripdata_samples/yellow_tripdata_sample_2019-03.csv
The batching_regex pattern matches the four digits of the year portion and assigns it to the year domain, and then matches the two digits of the month portion and assigns it to the month domain.
Run the following code to use the add_csv_asset function to add an Asset named csv_taxi_gcs_asset to your Data Source:
data_asset = datasource.add_csv_asset(
name="csv_taxi_gcs_asset",
batching_regex=batching_regex,
gcs_prefix=prefix,
)
You can add a BigQuery Asset into your Data Source as a table asset or query asset.
In the following example, a table Asset named my_table_asset is built by naming the table in your BigQuery Database.
table_asset = datasource.add_table_asset(name="my_table_asset", table_name="taxi_data")
In the following example, a query Asset named my_query_asset is built by submitting a query to the taxi_data table.
query_asset = datasource.add_query_asset(
name="my_query_asset", query="SELECT * from taxi_data"
)
Get a Batch and Create Expectation Suite
- Data in GCS
- Data in BigQuery
-
Use the
add_or_update_expectation_suitemethod on your Data Context to create an Expectation Suite:Pythoncontext.add_or_update_expectation_suite(expectation_suite_name="test_gcs_suite")
validator = context.get_validator(
batch_request=batch_request, expectation_suite_name="test_gcs_suite"
) -
Use the
Validatormethod to run Expectations on the Batch and automatically add them to the Expectation Suite.Pythonvalidator.expect_column_values_to_not_be_null(column="passenger_count")
validator.expect_column_values_to_be_between(
column="congestion_surcharge", min_value=-3, max_value=1000
)In this example, you're adding
expect_column_values_to_not_be_nullandexpect_column_values_to_be_between. You can replace thepassenger_countandcongestion_surchargetest data columns with your own data columns. -
Run the following code to save the Expectation Suite:
Pythonvalidator.save_expectation_suite(discard_failed_expectations=False)
-
Use the
table_assetyou created previously to build aBatchRequest:Pythonrequest = table_asset.build_batch_request() -
Use the
add_or_update_expectation_suitemethod on your Data Context to create an Expectation Suite and get aValidator:Pythoncontext.add_or_update_expectation_suite(expectation_suite_name="test_bigquery_suite")
validator = context.get_validator(
batch_request=request, expectation_suite_name="test_bigquery_suite"
) -
Use the
Validatorto run expectations on the batch and automatically add them to the Expectation Suite:Pythonvalidator.expect_column_values_to_not_be_null(column="passenger_count")
validator.expect_column_values_to_be_between(
column="congestion_surcharge", min_value=0, max_value=1000
)In this example, you're adding
expect_column_values_to_not_be_nullandexpect_column_values_to_be_between. You can replace thepassenger_countandcongestion_surchargetest data columns with your own data columns. -
Run the following code to save the Expectation Suite containing the two Expectations:
Pythonvalidator.save_expectation_suite(discard_failed_expectations=False)
Build and run a Checkpoint
- Data in GCS
- Data in BigQuery
-
Run the following code to add the
gcs_checkpointCheckpoint to the Data Context:Pythoncheckpoint = context.add_or_update_checkpoint(
name="gcs_checkpoint",
validations=[
{"batch_request": batch_request, "expectation_suite_name": "test_gcs_suite"}
],
)In this example, you're using the
BatchRequestandExpectationSuitenames that you used when you created your Validator. -
Run the Checkpoint by calling
checkpoint.run():Pythoncheckpoint_result = checkpoint.run()
-
Run the following code to add the
bigquery_checkpointCheckpoint to the Data Context:Pythoncheckpoint = context.add_or_update_checkpoint(
name="bigquery_checkpoint",
validations=[
{"batch_request": request, "expectation_suite_name": "test_bigquery_suite"}
],
)In this example, you're using the
BatchRequestandExpectationSuitenames that you used when you created your Validator. -
Run the Checkpoint by calling
checkpoint.run():Pythoncheckpoint_result = checkpoint.run()
Migrate your local configuration to Cloud Composer
Migrate your local GX configuration to a Cloud Composer environment to automate the workflow. You can use one of the following methods to run GX in Cloud Composer or Airflow:
In this example, you'll use the bash operator to run the Checkpoint. A video overview of this process is also available in this video.
Create and Configure a GCP Service Account
To create a GCP Service Account, see Service accounts overview.
To run GX in a Cloud Composer environment, the following privileges are required for your Service Account:
Composer WorkerLogs ViewerLogs WriterStorage Object CreatorStorage Object Viewer
If you are accessing data in BigQuery, the following privileges are required for your Service Account:
BigQuery Data EditorBigQuery Job UserBigQuery Read Session User
Create a Cloud Composer environment
See Create Cloud Composer environments.
Install Great Expectations in Cloud Composer
You can use the Composer web Console (recommended), gcloud, or a REST query to install Python dependencies in Cloud Composer. To install great-expectations in Cloud Composer, see Installing Python dependencies in Google Cloud. If you are connecting to data in BigQuery, make sure sqlalchemy-bigquery is also installed in your Cloud Composer environment.
If you run into trouble when you install GX in Cloud Composer, see Troubleshooting PyPI package installation.
Move your local configuration to Cloud Composer
Cloud Composer uses Cloud Storage to store Apache Airflow DAGs (also known as workflows), with each Environment having an associated Cloud Storage bucket. Typically, the bucket name uses this pattern: [region]-[composer environment name]-[UUID]-bucket.
To migrate your local configuration, you can move the local gx/ folder to the Cloud Storage bucket where Composer can access the configuration.
-
Open the Environments page in the Cloud Console and then click the environment name to open the Environment details page. The name of the Cloud Storage bucket is located to the right of the DAGs folder on the Configuration tab.
This is the folder where DAGs are stored. You can access it from the Airflow worker nodes at:
/home/airflow/gcsfuse/dags. The location where you'll uploadgx/is one level above the/dagsfolder. -
Upload the local
gx/folder by dragging and dropping it into the window, usinggsutil cp, or by clicking theUpload Folderbutton.After the
gx/folder is uploaded to the Cloud Storage bucket, it is mapped to the Airflow instances in your Cloud Composer and is accessible from the Airflow Worker nodes at:/home/airflow/gcsfuse/great_expectations.
Write the DAG and add it to Cloud Composer
- Data in GCS
- Data in BigQuery
-
Run the following code to create a DAG with a single node (
t1) that runs aBashOperator:Pythonfrom datetime import timedelta
import airflow
from airflow import DAG
from airflow.operators.bash import BashOperator
default_args = {
"start_date": airflow.utils.dates.days_ago(0),
"retries": 1,
"retry_delay": timedelta(days=1),
}
dag = DAG(
"GX_checkpoint_run",
default_args=default_args,
description="running GX checkpoint",
schedule_interval=None,
dagrun_timeout=timedelta(minutes=5),
)
# priority_weight has type int in Airflow DB, uses the maximum.
t1 = BashOperator(
task_id="checkpoint_run",
bash_command="(cd /home/airflow/gcsfuse/great_expectations/ ; great_expectations checkpoint run gcs_checkpoint ) ",
dag=dag,
depends_on_past=False,
priority_weight=2**31 - 1,
)The DAG is stored in a file named:
ge_checkpoint_gcs.pyThe
BashOperatorchanges the directory to/home/airflow/gcsfuse/great_expectations, where you uploaded your local configuration. -
Run the following command in the gcloud CLI to run the Checkpoint locally:
great_expectations checkpoint run gcs_checkpoint
To add the DAG to Cloud Composer, you move ge_checkpoint_gcs.py to the environment's DAGs folder in Cloud Storage. For more information about adding or updating DAGs, see Add or update a DAG.
-
Open the Environments page in the Cloud Console and then click the environment name to open the Environment details page.
-
On the Configuration tab, click the Cloud Storage bucket name located to the right of the DAGs folder.
-
Upload the local copy of the DAG.
-
Run the following code to create a DAG with a single node (
t1) that runs aBashOperatorPythonfrom datetime import timedelta
import airflow
from airflow import DAG
from airflow.operators.bash import BashOperator
default_args = {
"start_date": airflow.utils.dates.days_ago(0),
"retries": 1,
"retry_delay": timedelta(days=1),
}
dag = DAG(
"GX_checkpoint_run",
default_args=default_args,
description="running GX checkpoint",
schedule_interval=None,
dagrun_timeout=timedelta(minutes=5),
)
# priority_weight has type int in Airflow DB, uses the maximum.
t1 = BashOperator(
task_id="checkpoint_run",
bash_command="(cd /home/airflow/gcsfuse/great_expectations/ ; great_expectations checkpoint run bigquery_checkpoint ) ",
dag=dag,
depends_on_past=False,
priority_weight=2**31 - 1,
)The DAG is stored in a file named:
ge_checkpoint_bigquery.pyThe
BashOperatorchanges the directory to/home/airflow/gcsfuse/great_expectations, where you uploaded your local configuration. -
Run the following command in the gcloud CLI to run the Checkpoint locally::
great_expectations checkpoint run bigquery_checkpoint
To add the DAG to Cloud Composer, you move ge_checkpoint_bigquery.py to the environment's DAGs folder in Cloud Storage. For more information about adding or updating DAGs, see Add or update a DAG.
-
Open the Environments page in the Cloud Console and then click the environment name to open the Environment details page.
-
On the Configuration tab, click the Cloud Storage bucket name located to the right of the DAGs folder.
-
Upload the local copy of the DAG.
Run the DAG and the Checkpoint
Use one of the following methods to trigger the DAG:
To trigger the DAG manually:
-
Open the Environments page in the Cloud Console and then click the environment name to open the Environment details page.
-
In the Airflow webserver column, click the Airflow link for your environment to open the Airflow web interface for your Cloud Composer environment.
-
Click Trigger Dag to run your DAG configuration.
When the DAG run is successful, the
Successstatus appears on the DAGs page of the Airflow Web UI. You can also check that new Data Docs have been generated by accessing the URL to yourgcloudapp.
SQL
Connect GX to a SQL database to access Data Assets.
Prerequisites
- An installation of GX set up to work with SQL
- Source data stored in a SQL database
Import GX and instantiate a Data Context
Run the following Python code to import GX and instantiate a Data Context:
import great_expectations as gx
context = gx.get_context()
Determine your connection string
GX supports numerous SQL Data Sources. However, most SQL dialects have their own specifications for defining a connection string. See the dialect documentation to determine the connection string for your SQL database.
The following are some of the connection strings that are available for different SQL dialects:
- AWS Athena:
awsathena+rest://@athena.<REGION>.amazonaws.com/<DATABASE>?s3_staging_dir=<S3_PATH> - BigQuery:
bigquery://<GCP_PROJECT>/<BIGQUERY_DATASET>?credentials_path=/path/to/your/credentials.json - MSSQL:
mssql+pyodbc://<USERNAME>:<PASSWORD>@<HOST>:<PORT>/<DATABASE>?driver=<DRIVER>&charset=utf&autocommit=true - MySQL:
mysql+pymysql://<USERNAME>:<PASSWORD>@<HOST>:<PORT>/<DATABASE> - PostgreSQL:
postgresql+psycopg2://<USERNAME>:<PASSWORD>@<HOST>:<PORT>/<DATABASE> - Redshift:
postgresql+psycopg2://<USER_NAME>:<PASSWORD>@<HOST>:<PORT>/<DATABASE>?sslmode=<SSLMODE> - Snowflake:
snowflake://<USER_NAME>:<PASSWORD>@<ACCOUNT_NAME>/<DATABASE_NAME>/<SCHEMA_NAME>?warehouse=<WAREHOUSE_NAME>&role=<ROLE_NAME>&application=great_expectations_oss - SQLite:
sqlite:///<PATH_TO_DB_FILE> - Trino:
trino://<USERNAME>:<PASSWORD>@<HOST>:<PORT>/<CATALOG>/<SCHEMA>
Run one of the connection strings in your preferred SQL dialect to store the connection string in the connection_string variable with plain text credentials. The following code is an example of the PostgreSQL connection string format:
connection_string = "postgresql+psycopg2://username:my_password@localhost/test"
You can use environment variables or a key in config_variables.yml to store connection string passwords. After you define your password, you reference it in your connection string similar to this example:
connection_string = (
"postgresql+psycopg2://<username>:${MY_PASSWORD}@<host>:<port>/<database>"
)
In the previous example MY_PASSWORD is the name of the environment variable, or the key to the value in config_variables.yml that corresponds to your password.
If you include a password as plain text in your connection string when you define your Data Source, GX automatically removes it, adds it to config_variables.yml, and substitutes it in the Data Source saved configuration with a variable.
Create a SQL Data Source
Run the following Python code to create a SQL Data Source:
datasource = context.sources.add_sql(
name="my_datasource", connection_string=connection_string
)
Connect to the data in a table (Optional)
-
Run the following Python code to set the
asset_nameandasset_table_namevariables:Pythonasset_name = "my_asset"
asset_table_name = my_table_name -
Run the following Python code to create the Data Asset:
Pythontable_asset = datasource.add_table_asset(name=asset_name, table_name=asset_table_name)
Connect to the data in a query (Optional)
-
Run the following Python code to define a Query Data Asset:
Pythonasset_name = "my_query_asset"
query = "SELECT * from yellow_tripdata_sample_2019_01" -
Run the following Python code to create the Data Asset:
Pythonquery_asset = datasource.add_query_asset(name=asset_name, query=query)
Add additional tables or queries (Optional)
Repeat the previous steps to add additional Data Assets.